
2024年-2025年の年末年始で独自の生成AIモデルをイチから作ってみたので、やったことを共有する。この記事を読むと生成AIの中身ってどうなっているの?っていう疑問が少しでも無くなるのではないかと思うのでぜひ最後まで読んでもらいたい。
ちなみに最終的な成果物としては、コマンドライン上で動くAIチャットボットのようなものを作る。
※初めに断っておくが、本記事はまだ作成途中である。ひとまず現状版を公開する。
作業の流れ
まず初めに作業の流れをまとめる。具体的には下記のながれ。
それぞれ解説していく。
MultiHeadAttentionを実装する
今回は初代GPTのアーキテクチャーを参考にLLMを実装する。下記はGPTの論文から引用した図である。
図の左側の部分を見ると、「Layer Norm」「Feed Forward」「Masked Multi Self Attention」というコンポーネントで構成されていることがわかる。そのため、この中で一番難しそうな部分である「Masked Multi Self Attention」を実装すべく、まずはその大元となるMultiHeadAttentionを実装した。
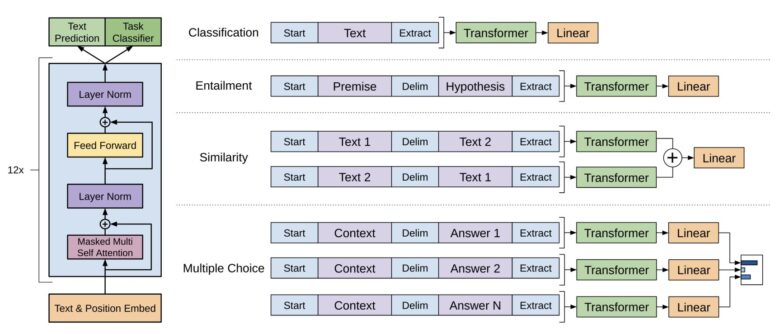
引用:Improving Language Understanding by Generative Pre-Training
ということで早速MultiHeadAttentionの実装。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, num_heads):
super(MultiHeadAttention, self).__init__()
# 分割するヘッド数が割り切れるかどうかチェック
assert embed_size % num_heads == 0
self.embed_size = embed_size
self.num_heads = num_heads
self.head_dim = embed_size // num_heads
# クエリー、キー、バリューの生成レイヤを定義
self.project_query = nn.Linear(embed_size, embed_size)
self.project_key = nn.Linear(embed_size, embed_size)
self.project_value = nn.Linear(embed_size, embed_size)
# 最終層の定義
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, query, key, value, mask=None):
# バッチサイズを保持
num_batch = query.shape[0]
# トークンサイズを保持
seq_length = query.shape[1]
# キー、クエリ、バリューの生成
query = self.project_query(query)
key = self.project_key(key)
value = self.project_value(value)
# マルチヘッドに分割する
# transposeは指定した次元を入れ替える
queries = query.view(num_batch, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
keys = key.view(num_batch, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
values = value.view(num_batch, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
energy = torch.einsum("nhql,nhkl->nhqk", queries, keys)
if mask is not None:
energy = energy.masked_fill(mask==0, float("-1e20"))
attention = F.softmax(energy / (self.head_dim ** 0.5), dim=-1)
out = torch.einsum("nhqk,nhvl->nhql", attention, values)
out = out.transpose(1, 2).contiguous().view(num_batch, seq_length, self.embed_size)
return self.fc_out(out)Transformerブロックを実装する
次にTransformerブロックを実装する。ここで登場するMultiHeadAttentionは直前に実装したものを使用している。
from multi_head_attention import MultiHeadAttention
import torch.nn as nn
class TransformerBlock(nn.Module):
def __init__(self, embed_size, num_heads, dropout_rate, forward_expansion):
super(TransformerBlock, self).__init__()
# Masked Multi-Head Attention
self.attention = MultiHeadAttention(embed_size=embed_size, num_heads=num_heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size)
)
self.dropout = nn.Dropout(dropout_rate)
def forward(self, query, key, value, mask):
# Masked Self-Attention
masked_attention_out = self.attention(query, key, value, mask)
# Add & Norm
x = self.norm1(masked_attention_out + query)
x = self.dropout(x)
# Feed Forward Network
forward_out = self.feed_forward(x)
# Add & Norm
x = self.norm2(forward_out + x)
return self.dropout(x)DecoderOnlyModelを実装する
DecoderOnlyModelの実装は下記。ここでもTransformerBlockは直前で実装したものを使用している。
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformer import TransformerBlock
class DecoderOnlyModel(nn.Module):
def __init__(self, vocab_size, embed_dim, num_layers, max_seq_len, num_heads, dropout_rate=0.1):
super(DecoderOnlyModel, self).__init__()
# vocab_sizeは扱うトークンIDの種類を表す
self.vocab_size = vocab_size
self.embed_dim = embed_dim
self.max_seq_len = max_seq_len
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.positional_encoding = self._generate_positional_embedding(embed_dim, max_seq_len)
self.transformer_blocks = nn.ModuleList([
TransformerBlock(embed_dim, num_heads, dropout_rate, 4) for _ in range(num_layers)
])
self.layer_norm = nn.LayerNorm(embed_dim)
self.output_layer = nn.Linear(embed_dim, vocab_size)
def forward(self, input_ids):
batch_size, seq_len = input_ids.size()
embeddings = self.embedding(input_ids)
# 位置エンコーディングの値をトークンの長さ分取り出す。その後バッチの数だけ複製する。
pos_encoding = self.positional_encoding[:seq_len, :].unsqueeze(0).expand(batch_size, -1, -1)
x = embeddings + pos_encoding
for transformer_block in self.transformer_blocks:
seq_mask = torch.tril(torch.ones(seq_len, seq_len)).unsqueeze(0).unsqueeze(0).to(x.device)
x = transformer_block(x, x, x, seq_mask)
x = self.layer_norm(x)
return self.output_layer(x)
def _generate_positional_embedding(self, embed_dim, max_seq_len):
# pytorchのtorch.agange()はデフォルトでint64になるため。torch.floatを指定してfloat32にする
position = torch.arange(0, max_seq_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, embed_dim, 2).float() * (-torch.log(torch.tensor(10000.0)) / embed_dim))
pe = torch.zeros(max_seq_len, embed_dim)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
return peChatModelを実装する
最後に今まで作ったモデルをChat形式で使えるようにする。コードは下記。なお、いつも通りDecoderOnlyModelは直前で実装してものを使用。
from transformers import AutoTokenizer
import torch
import torch.nn.functional as F
from decoder_only_model import DecoderOnlyModel
class ChatLLM:
def __init__(self, vocab_size, embed_dim, num_layers, max_seq_len, num_heads, temperature=1.0):
self.max_seq_len = max_seq_len
self.tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese")
self.model = DecoderOnlyModel(
vocab_size=vocab_size,
embed_dim=embed_dim,
num_layers=num_layers,
max_seq_len=max_seq_len,
num_heads=num_heads
)
self.temperature = temperature
self.eos_token_id = self.tokenizer.eos_token_id or self.tokenizer.sep_token_id
def chat(self, prompt):
# 入力をトークン化
input_ids = self.tokenizer(prompt, return_tensors="pt")["input_ids"]
# 生成結果を保持する
generated_ids = input_ids.clone()
# 最大長までのトークンを生成
for _ in range(self.max_seq_len - input_ids.size(1)):
# モデルからロジットを取得
logits = self.model(generated_ids)
# 最新トークンのロジットを取得
next_token_logits = logits[:, -1, :]
# ソフトマックスを適用して確率を計算
probs = F.softmax(next_token_logits / self.temperature, dim=-1)
# 確率に基づいて次のトークンをサンプリング
next_token_id = torch.multinomial(probs, num_samples=1)
# 生成結果に次のトークンを追加
generated_ids = torch.cat((generated_ids, next_token_id), dim=1)
# 終了トークンを検出した場合に終了
if next_token_id.item() == self.eos_token_id:
break
# 生成されたトークンをデコードして返す
return self.tokenizer.decode(generated_ids[0], skip_special_tokens=True)
# モデルのパラメータを指定
vocab_size = 32000
embed_dim = 512
num_layers = 6
max_seq_len = 128
num_heads = 8
# ChatLLM インスタンスを生成
chat_model = ChatLLM(
vocab_size=vocab_size,
embed_dim=embed_dim,
num_layers=num_layers,
max_seq_len=max_seq_len,
num_heads=num_heads,
temperature=0.8
)
# サンプルプロンプトでチャット
response = chat_model.chat("こんにちは、今日はどんな話をしましょうか?")
print(response)なお、今回のコードについては僕のGitHubリポジトリに公開している。そちらも参照していただきたい。
※次回の記事ではここで作ったLLMを実際に学習させてみる。乞うご期待。
まとめ:生成AIモデルのコードって意外と単純だった
今回実際にイチから生成AIモデルを実装してみたが、この活動を通して意外とアルゴリズム的には単純であるのだと思った。単純な構造を何層も重ねて計算量を莫大にして精度を向上させているのだと思った。
「生成AIって力づくで精度を上げているんでしょ」って今まで思っていたが、実際にアルゴリズムを理解したことでやっぱりその通りなのだと確信できた。
AIという、よくわからないブラックボックスな機構を分解してアルゴリズムを理解できるのがAIエンジニアの醍醐味であると僕は思う。今後もこのような自由研究的な作業をやっていきたい。